Sorbet thinks that loop_count is nil at the
start of the rescue block, which causes it to declare the
puts line unreachable (because nil is never
truthy).
But why? Clearly we can see that loop_count is an
Integer. We’d expect Sorbet to at least think
loop_count has type T.nilable(Integer), if not
simply Integer outright.
Sometimes Sorbet takes shortcuts—especially when the short cut is
good enough 99% of the time while being simple and fast. Sorbet’s
approach to rescue and exception handling is one of these
shortcuts.
Control flow and
rescue in Sorbet
I mentioned in my last post
that Sorbet builds a control flow
graph (CFG) in order to model control-flow sensitive
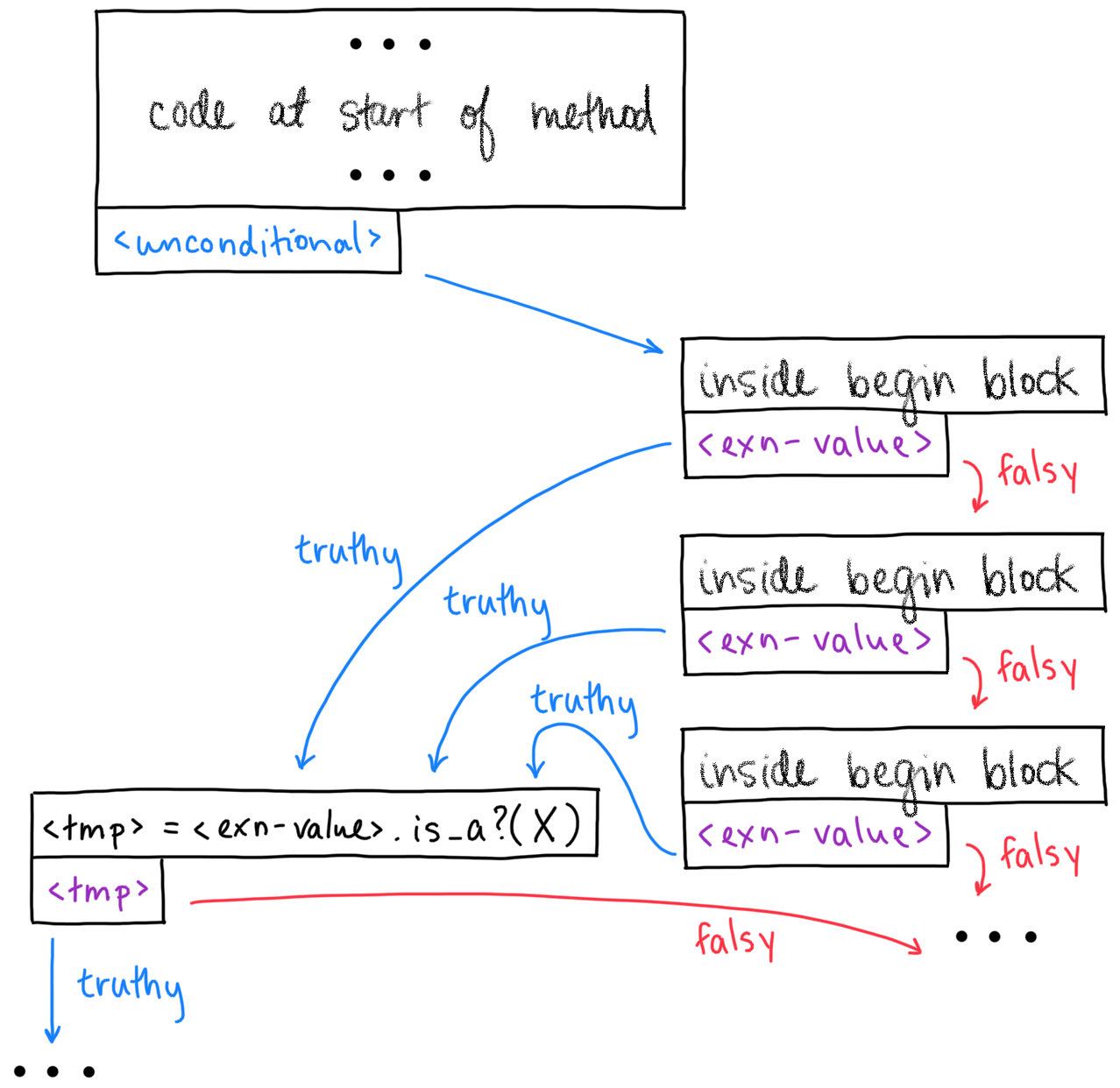
types throughout the body of a method. For rescue nodes, it
pretends that there are only two jumps into the rescue
block: once before any any code in the
begin block has run, and once after all the code in
begin block has run. It looks a little something like
this:
An example CFG with a rescue
block
An example CFG with a rescue
block
If you have Graphviz installed,
you can get Sorbet to dump its internal CFG for a given file with the
cfg-view.sh script in the Sorbet repo. The CFG for the
example above looks like like this.
This is a simplified view of a CFG in
Sorbet.
The boxes contain hunks of straight-line code (code without control
flow), and all control flow is made explicit by branching on a specified
variable at the end of each block. For the case of rescue,
the branches read from a magical <exn-value>
variable, which Sorbet treats as unanalyzable: Sorbet doesn’t
attempt to track how the value is initialized nor how control flow
affects it.
Knowing this, we can explain the weird dead code error from the
snippet above:
The first jump into the rescue block happens before any
code in the begin block runs. At that point, the
loop_count variable is still uninitialized, and thus has
type NilClass when taking that branch.
The second jump into the rescue block happens after the
begin block finishes. But from Sorbet’s point of view, the
begin block in the loop_count snippet never
finishes! Sorbet sees the infinite while true loop and
says, “it doesn’t matter where to branch at the end of the
begin block—the infinite loop won’t allow control to flow
there.”If you’re fearless, you can prove that this is what’s
happening in the rendered
CFG for the above example.
Despite it being able to tell that
loop_count has type Integer inside the
begin, only the NilClass branch is live in the
rescue block.
Of course, easier said than done.
That second point about while true is simply a bug.
Sorbet should be smart enough to suspend the normal flow-sensitivity
rules for infinite loops while checking code in a begin
block that has a
rescue.
But still, fixing that bug would only fix half the problem: Sorbet would
think that loop_count has type
T.nilable(Integer) in the rescue body, but we
said the best outcome would be for Sorbet to know that
loop_count is always initialized, having
type Integer.
Before we can see what it would take for Sorbet to infer
Integer, some history.
A brief history of
rescue in Sorbet
Sorbet’s first
commit dates to October 3, 2017. Six weeks later, the initial
support for rescue landed. The pull request description
is from a time when all pull requests were not public, so I’ll quote it
here:
This does most of the work in the CFG, preserving the semantics in
the desugarer. […]
It introduces a series of uncomputable ifs since 0 or
more instructions from the first block will execute then one of the
rescues could match and then if none do the
else will match.
This is not quite true: x = 0 doesn’t raise, and Sorbet
can see that syntactically. This
might be something to take advantage of in the future.
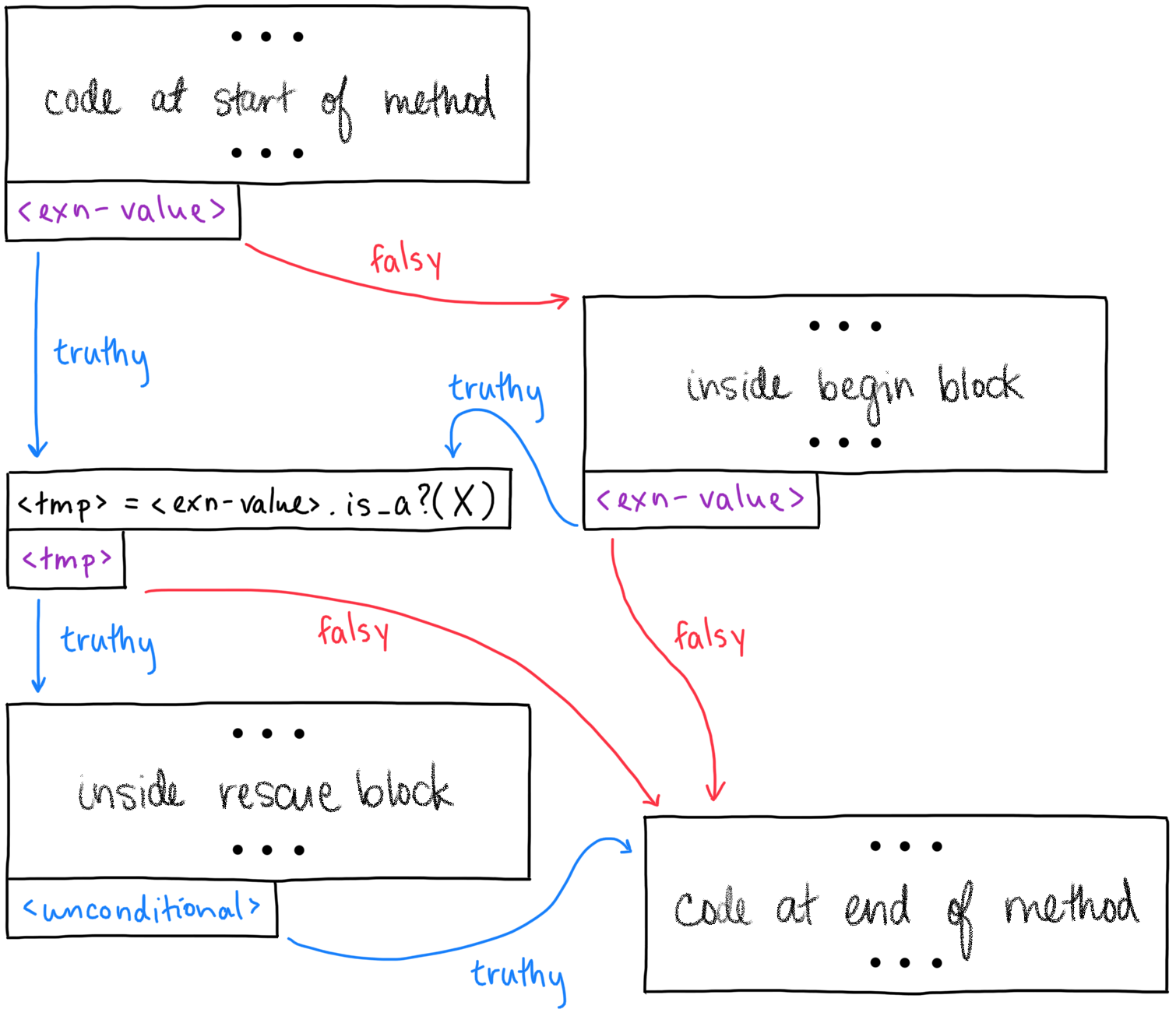
The approach it’s describing is what most people might do
intuitively: any instruction in a begin might
raise,
so let’s record an unanalyzable jump after each instruction, into the
rescue block. In picture form:
A diagram depicting the implementation
described in the above commit
A diagram depicting the implementation
described in the above commit
Note how every line of the begin body gets its own, tiny
basic block with an unanalyzable jump to the rescue block,
or to the next line of the body. This implementation wouldn’t have
exhibited the bug in our loop_count example—there would be
a jump after the loop_count = 0 assignment into the
rescue block, which would have been enough for Sorbet to
infer a type of Integer (regardless of whether that
while true bug were fixed method).
And only two days after I joined the team 😅
But importantly, this original approach was thrown out, almost
exactly 9 months
later,
when the shortcut we’ve been discussing arrived. In fact, a comment from
that commit persists unchanged in the codebase today:
We have a simplified view of the control flow here but in practise it
has been reasonable on our codebase. We don’t model that each expression
in the body or else could throw, instead we
model only never running anything in the body, or running the whole
thing. To do this we have a magic Unanalyzable variable at the top of
the body using rescueStartTemp and one at the end of the
else using rescueEndTemp which can jump into the rescue
handlers.
Why adopt this shortcut approach if it causes bugs like this
to happen? Well for starters, the original approach had an even more
insidious bug. Consider this example:
begin x = might_raise()# ...rescue# Sorbet would assume `x` was always setputs(x)end
There’s an easy workaround: use T.let to pin the type of
the variable outside the begin block.
In this example, the first instruction in the block is an assignment
(x = ...). But Sorbet would only record the jump after the
assignment entirely, not between the method call and the assignment.
This meant Sorbet would think that x was unconditionally
set, but in fact it’s not set when
might_raise() does actually raise. At the time, Sorbet
tripped this bug all the time on real-world code—there were beta users
of Sorbet chiming in on the PR eagerly waiting for the bug to be fixed.
Meanwhile, code that looked like our loop_count example
either did not exist or was simply
rewritten
to avoid the bug.
But this still doesn’t quite paint the full picture. I’ve told you,
“There was a bug, and Sorbet fixed it by introducing another bug.” Which
leads us to out second point: having a lot of tiny, jumpy basic blocks
is slow to typecheck. There are lots of reasons:
After building a CFG, Sorbet does a bunch of post-processing on
it. For example, it computes which variables each basic block reads and
writes, tries to dealias variable writes, and merges adjacent blocks if
possible. When there are fewer basic blocks, these post-processing steps
run faster to begin with, and are more likely to drastically shrink the
CFG size (making type inference run faster).
When typechecking a method, every basic block in the CFG requires
its own Environment
data structure, which maps variables to their types within that block.
Sorbet either has to allocate a separate Environment per
block (what it currently does) or incur complexity from making them copy-on-write. Allocating is
slow and we really like to avoid complexity.
Before typechecking a basic block, Sorbet has to merge the
environments of all incoming blocks. Merging environments involves doing
slow type checking operations, like checking whether two
possibly-arbitrary types are subtypes of each other and allocating union
types.
Not only are there more basic blocks, there are more
instructions! Each <exn-value> variable has to be
populated before Sorbet can branch on it, and that each tiny basic block
has not only the single instruction inside it, but also an extra
instruction to initialize the <exn-valu> variable.
That basically doubles the number of instructions Sorbet emits for a
begin block, making more work for type inference.
The new “only before and after” shortcut is pretty clever. In
practice, it models the case when even the very first assignment might
raise, while generating far fewer basic blocks, thus running much
faster.
The bigger picture
There are a lot of these clever “good enough” tricks in Sorbet. Many
of them are only possible because of the stakes: Sorbet already
allows T.untyped, so
depending on your viewpoint, either:
There is already the holy grail of all hacks in the type system, so
why not cut more corners when it makes sense.
BecauseT.untyped is in the type system, at
least the user can use T.untyped to not be completely
blocked from writing the code they need to write.
Either way, in some sense the stakes are low. In a compiler where the
stakes for being wrong are higher (the code computes the wrong answer),
maybe shortcuts aren’t the best idea. And in fact, multipledistinctexceptionchanges landed in
Sorbet’s CFG code to support the Sorbet Compiler.
It’s now been over four years since we shipped the change to model
rescue this way. I’m not aware of a single incident caused
by this shortcut, and I can only even remember explaining this behavior
to a confused Sorbet user twice. I can’t find any performance numbers
from when the original change landed, but we can still put it into
perspective: it’s the difference between a handful of people being
confused over the course of 4 years, or thousands of people getting
faster typechecking results thousands of times per day. Seems like a
reasonable trade-off.
{kind=link}