My main focus last year was improving the Sorbet editor experience: making Sorbet feel snappier while powering language-aware editor features. The biggest improvements came from making Sorbet more incremental. By being smarter about skipping redundant work, we slashed the time it takes for Sorbet to do things like update the list of errors, populate autocompletion suggestions, and jump between definitions and usages.
I had a lot of fun working on this, so I’m going to gush about it. It’s going to be long—don’t say I didn’t warn you. But I think it’s also really cool.
Every edit in Sorbet is different—some edits are simply more work to type check than others. For example, it’s a lot more work to type check an edit that changes thousands of files than it is to type check an edit that adds a blank line inside a method body. Ideally Sorbet would figure out what’s changed and use that to type check only as much as necessary.
But Sorbet takes a bit of an unconventional approach to incrementality. In particular, it’s not fully incremental: some kinds of edits cause Sorbet to type check the whole codebase. The changes we built last year made this happen much less often: from 19% of edits when we started to only 10% of edits by the end.
Incrementally responding to an edit is hard for three vague reasons:
- It’s hard to quickly tell what changed.
- Knowing that, it’s hard to correctly update Sorbet’s knowledge of the codebase.
- Having done that, it’s hard to decide which files depend on what changed and must be type checked again.
Sorbet is stateful, so even a minor bug in solving one of those problems will compound as more edits arrive.
Of those three, Sorbet managed to do (1) and (3) passably well before we started. But (2) is classically the hardest of the three, and Sorbet avoided it in all but the simplest of cases—partly by design! In Reflections on software performance, Nelson wrote:
In the case of Sorbet, while we did make use of some caches, and while Sorbet’s LSP server has some complexity to perform incremental re-typechecking, both systems were drastically simpler than the ones in comparable typecheckers I am familiar with. We got away with this simplicity in large part because the base-case performance for Sorbet just isn’t that bad; Sorbet doesn’t have to go to extreme lengths to save work, because it’s often fast enough to just do the work instead.
Unfortunately, after about 5 years of codebase growth, the base-case performance had slowed to a point where it was no longer fast enough to just do the work. It was finally time to make Sorbet more incremental, which we went about in two steps:
- Step 1: enumerate all the kinds of edits that could happen
- Step 2: teach Sorbet how to incrementally update its knowledge for each kind of edit
Step 1: List all the edits
One of the cool things about Sorbet is how easy it is to get metrics out of it.
Whenever Sorbet gives up on handling an edit incrementally, it emits a metric with the reason. In June 2022, the breakdown looked something like this on Stripe’s codebase:
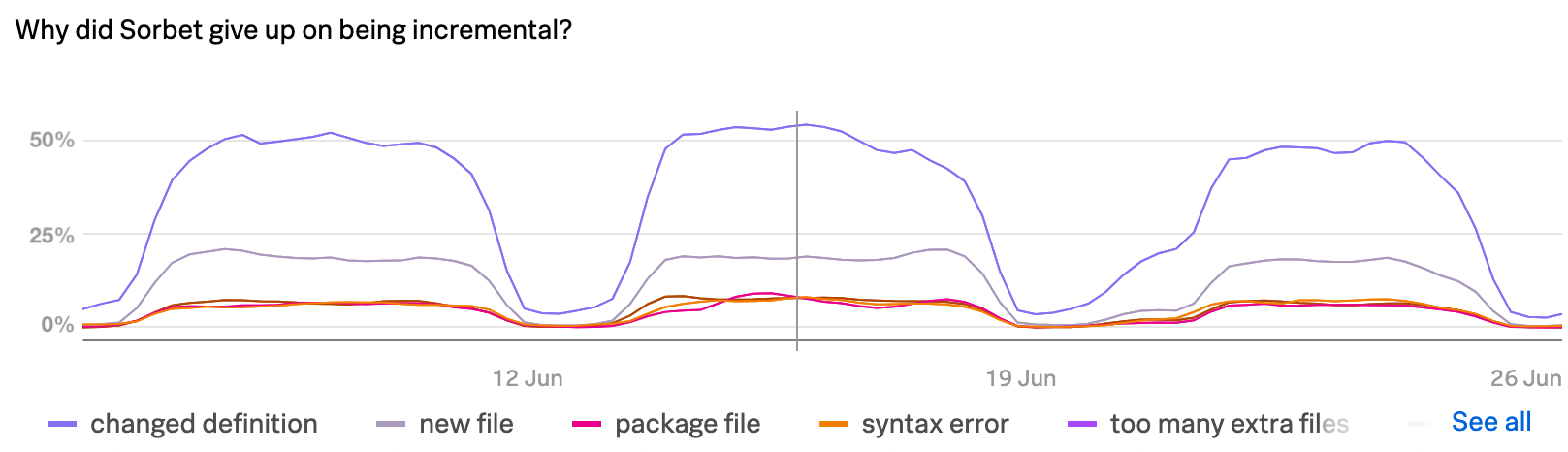
This chart shows that the most common reason was “changed definition,” accounting for 50% of edits that ended in a full type check. “Changed definition” here means any change to a method, class, module, constant, generic type, or instance variable. (Basically: everything but local variables.) Maybe a definition’s type changed, maybe its name changed, maybe it was added or deleted, etc.
Given how common the “changed definition” bucket was, we decided to focus on it first. (I’ll circle back to the other reasons when discussing what’s next below.)
Digging in one step further, next we listed what kinds of definitions were changing in those “changed definition” slow path edits:
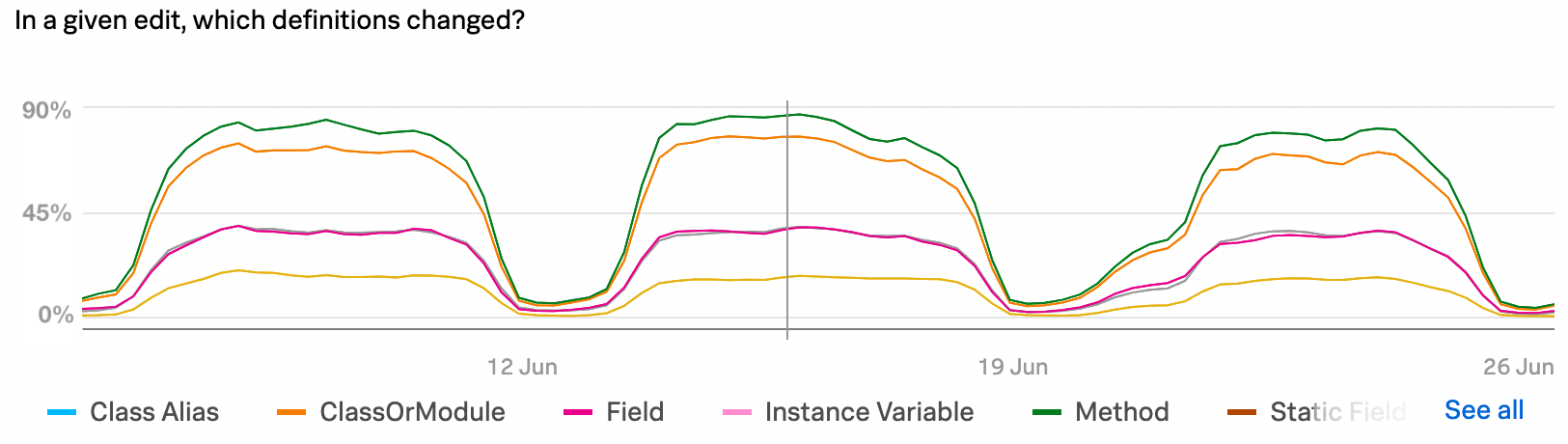
The chart confirms what you might have already expected: method and class definitions are commonly changed. Slightly less common are edits to instance variables, constant assignments, and certain things like generic types.
But you’ll notice that the percents here sum to over 100%, because one edit might change more than one kind of definition. If we were to teach Sorbet how to handle changes involving, say, method definitions, it might still have to take the slow path if the edit also changed a class.
So we looked at one last breakdown: in changed definition edits where only one kind of definition changed, which kind was it:
Sorry for the poor screenshot here, but the blue line
on top is for changes to only method definitions.
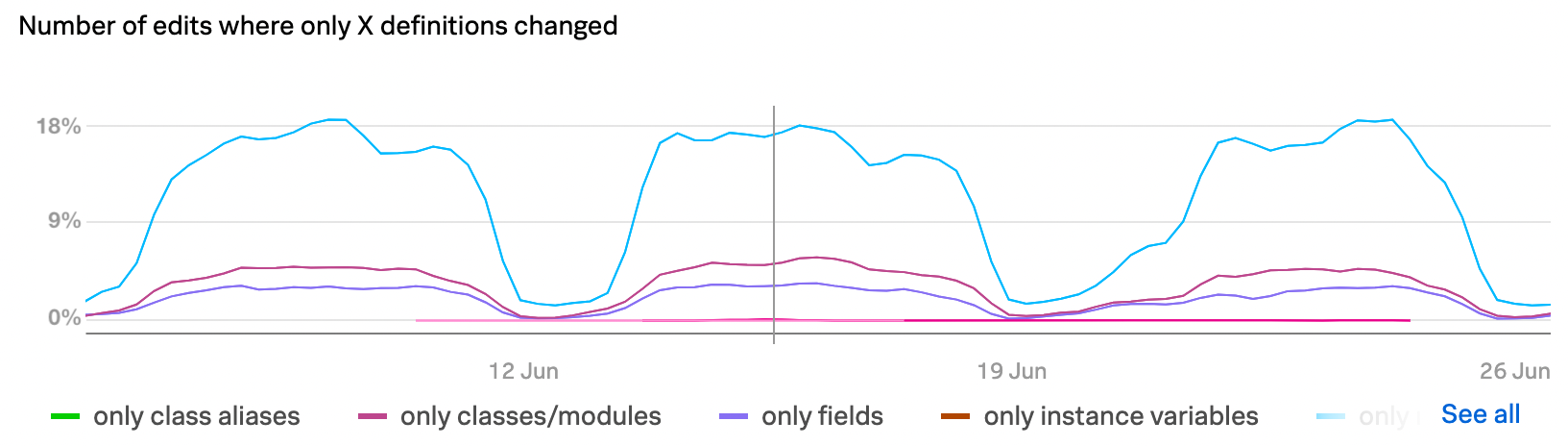
Not every edit changes only one kind of definition, so these lines don’t sum to 100%. But data like this is still great because it tells us what to prioritize.
With this, step 1 was done: we’d listed all the kinds of edits that Sorbet chokes on, and figured out the order we should tackle them.
Next came the hard part—actually teaching Sorbet how to incrementally update its knowledge in response to each one of these edits.
Step 2: A poor man’s incrementality
TypeScript is an exception, but that’s because it was written by the same person who had done the C# rewrite.
There are all sorts of principled ways to build an incremental compiler. Anders Hejlsberg describes one approach here, used by C# and TypeScript. Alex Kladov describes another approach here, used by rust-analyzer. The problem with every principled approach I’ve seen is that in practice, it involved a full or near-full rewrite of the codebase. From what I can tell, that took about 3 years for C#, and about 3 years for rust-analyzer.
I don’t have that kind of time, so we came up with a different approach: when a file changes, delete all its old stuff, then define all its new stuff. This lets Sorbet continue to assume that it has up-to-date information about the while codebase, while still being incremental.
In a picture, it looks a little like this:
Funnily enough, Anders’ video explicitly calls out
approaches like this, saying “That’s too complicated. I’ve never seen a
system succeed that does that.” (19:10) I’m not sure whether to take
that as a point of a pride or a warning of impending doom.
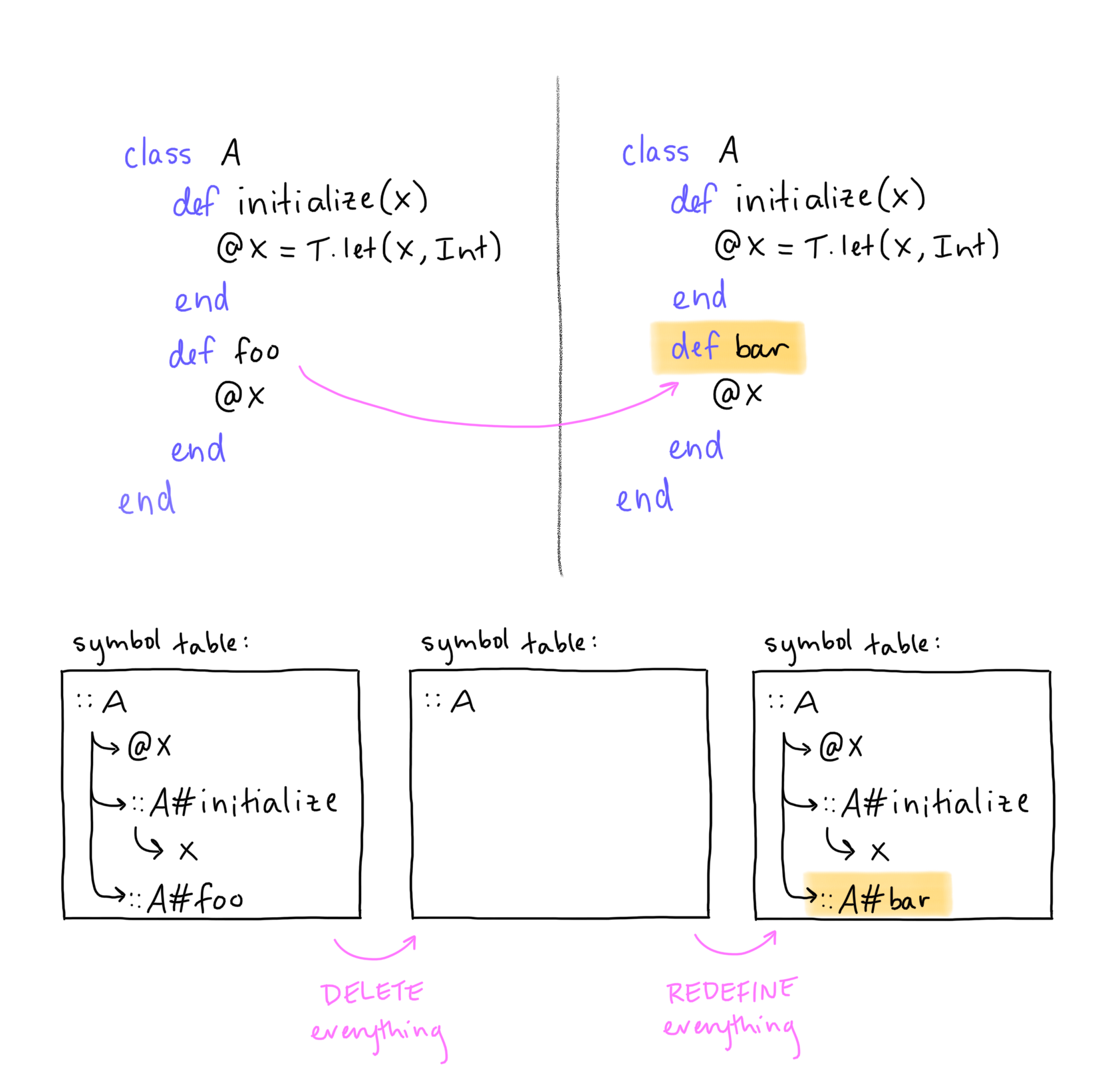
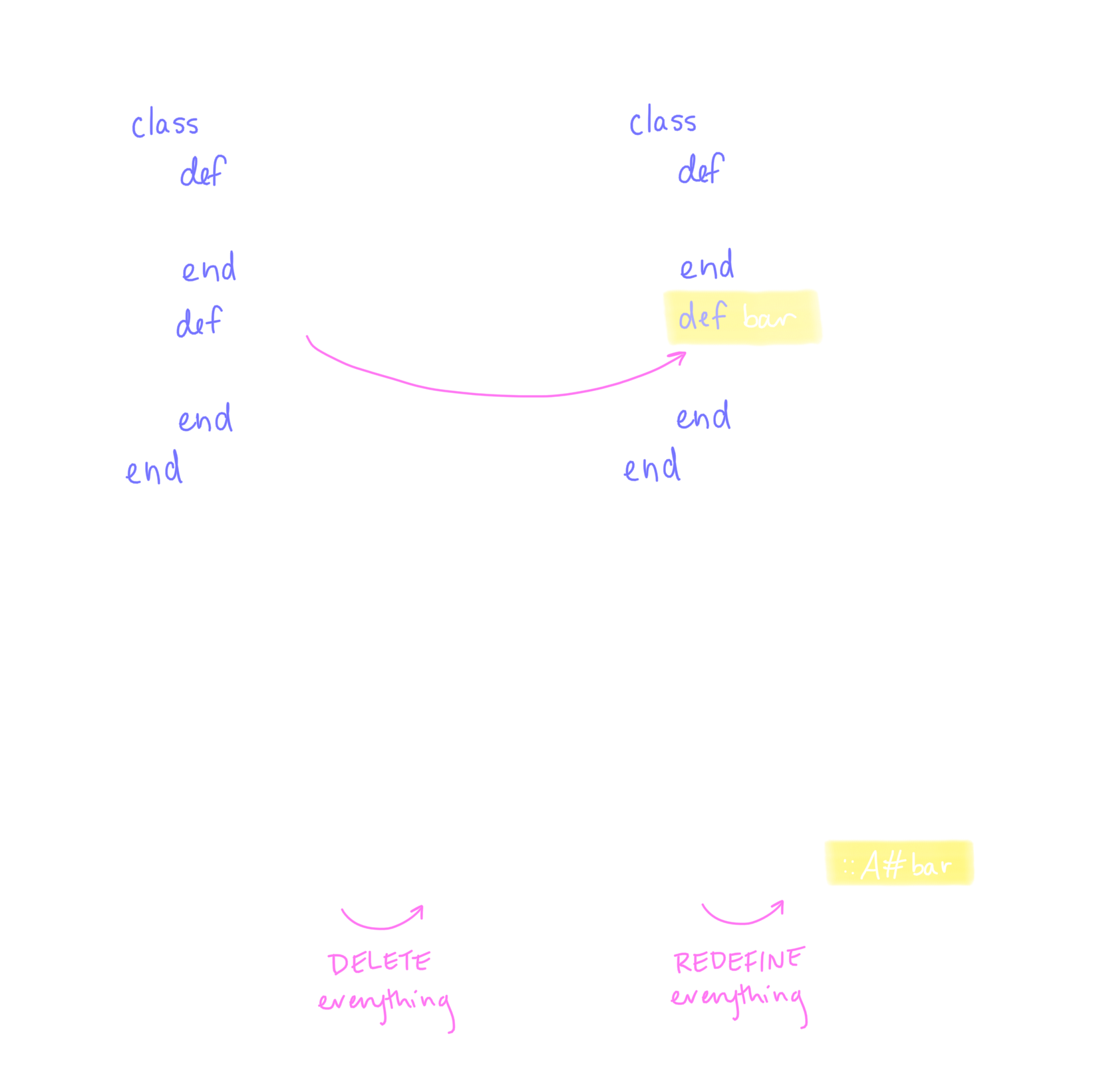
This approach sidesteps an annoying problem: we don’t have to figure out whether a definition was added, deleted, renamed, or moved, nor how to mutate the state in response. Rather, we just toss out everything. This is great! Sorbet already has code that’s meant to define everything inside a file, so we’re free to focus on the smaller problem of how to toss out the old stuff.
Another great side-effect: by reusing the code that registers everything a file defines, we bring along all the runtime assertions which enforce Sorbet’s internal invariants. Maintaining invariants is the only thing that makes working on a project like Sorbet tractable!
And finally, this approach is quite practical—it doesn’t require landing one huge change. Instead, the change can be built and deployed one kind of definition at a time, ordered by the data we collected in step 1. This allows for steady, low-risk progress over the project’s lifetime. In particular, we got the change working for method definitions specifically only two months into the project.
At the end of the day while this model for incrementality is far from ideal, it’s simple and it’s fast enough. Importantly, it restricts the work required to handle an edit to the size of the edit, instead of type checking the entire codebase, which is many orders of magnitude larger than the size of an edit.
After a few months of prototyping, we had rolled out support for deleting and redefining methods, then we followed up with instance and class variables and finally constant assignments and type members. The only definition kind that we haven’t handled yet is class and module definitions, which I’ll discuss in a moment.
Wait, what took so long?
“You’ve made things out as though this is all very simple. Then what took so long? You’ve been working on this for months.” For the sake of explanation I’ve papered over a lot of subtlety. Here’s a sense of what I papered over:
It took us a while to arrive at the exact idea presented
here.
My first attempts tried and failed to do smarter things, like track
additions, deletions, renames, and moves.
It’s only from attempting to implement it that I realized the “delete everything” approach would be simpler and also good enough.
“Delete everything” is simpler, but not
simple.
You still have to figure out what “everything in a file” is, which
Sorbet had no need to track this before. It simply tracked “everything
in the codebase.”
Also, some parts of Sorbet clung to the idea that nothing would be deleted. While we like to have a single source of truth for all bits of knowledge, sometimes I was surprised to find places where Sorbet effectively had more than one source of truth, which caused problems when deleting one source but forgetting the other.
Lots of code needed restructuring.
Most of the refactors were to work around the fact that we avoided
deleting class and module definitions. Our approach for figuring out
what to delete involves an assumption that the edit changes neither
classes nor modules.
Even still, getting Sorbet to a state where we could take advantage of that assumption involved no fewer than 12 changes to restructure Sorbet’s internals.
We wanted to be very deliberate about testing and
correctness.
Probably half of the time or more was spent thinking of weird and wacky
sequences of edits to expose potential bugs.
We couldn’t just rely on the existing tests, because tests for Sorbet’s incremental mode previously accounted for only 2% of all Sorbet tests. We 4x’d that, and now 8% of all Sorbet tests are specifically testing the incremental mode.
As we kept writing tests, we kept finding
bugs.
Most of these bugs were problems in the change itself. But some were
pre-existing bugs in Sorbet!
The sheer volume of new tests we wrote helped find minimal reproducers for many bugs that we knew of but couldn’t pin down. In particular, we found and fixed the most common source of production crashes in Sorbet: a problem with updating source location information.
We also ran into a snag in our first production rollout where a bug meant that older Sorbet versions wouldn’t evict on-disk caches created by newer Sorbet versions in certain situations. We had to roll back our first attempt to ship methods and fix this bug before proceeding.
And finally, for a three-week stretch somewhere in the middle, I nerd sniped myself into fixing a couple dozen bugs in Sorbet’s support for generics. This had nothing to do with incrementality but was was a lot of fun and a welcome break from pure performance work.
While this approach definitely has limitations, in practice it’s had a huge impact for a low cost. Sorbet feels much snappier, even if sometimes it still isn’t perfect. A few months is a pretty great return for the amount of incrementality we got in return.
Can we make everything incremental?
At the top of the post, I mentioned that the current split of incremental to non-incremental is 90/10. For the 10% of edits that still require a full type check, here’s how often each of the slow path reasons show up, and what it would take to address them:
33% of slow path edits – changed definitionSince slow path edits are 10% of all edits, this
bucket accounts for 3.3% of all edits.
At this point, the only definitions that are not handled incrementally
are class and module definitions.
This bucket is the trickiest, as some of the approaches we described for deleting everything break down with classes. We still have a few ideas, but this is the biggest unknown.
28% of slow path edits – new file
This bucket represents any time Sorbet sees an edit that creates a
file.
In practice, handling new empty files is not hard, but the first thing someone does in a new file is define a class or a module. So while fixing this bucket is easy, it’s blocked on “changed definition” above, to the point where it’s almost better to lump these buckets together and say that “changed definition” is the cause of 61% of slow path edits.
13% of slow path edits – too many extra files
This bucket represents when a small number of files were edited
and Sorbet could have processed the edit incrementally,
but it would have involved type checking hundreds or thousands of files
that didn’t change. Sorbet’s incremental mode is currently single
threaded and can’t be interrupted, so naively attempting to handle these
edits incrementally would have the effect of locking the user out for a
long time.
Fixing this bucket should be as simple as taking all the fancy things we do to handle large slow path edits in parallel and making them work for incremental edits too.
10% of slow path edits – too many files
This bucket represents when the number of changed files was large.
Historically, since it was so rare for large edits to be handled
incrementally, we short circuited as a performance optimization.
There’s no technical limitation why we can’t treat these edits like other edits (except for maybe ironing out some kinks).
9% of slow path edits – package fileNot much has been written about how these files work,
but it’s all built into Sorbet and open source. If you’re curious, you
can dig into the test suite and see them in action.
__package.rb files are special Ruby files used in Stripe’s
codebase to enforce public/private boundaries owned by different teams.
This bucket represents any change in one of these files.
Handling these files shouldn’t be much harder than how handling method public/private visibility incrementally works today.
7% of slow path edits – syntax error
This bucket represents when Sorbet parsed a Ruby file, encountered a
syntax error, and failed to recover, producing an empty
parse tree.
First, bear in mind that this is the smallest bucket, accounting for only 0.7% of all edits! Arguably Sorbet is already quite good at recovering from syntax errors.
But second, if Sorbet could handle changes to class or module definitions incrementally, then “failing to parse a file” looks the same as “deleting every definition in the file.” So really, we might want to bucket this in with “changed definition.”
That brings our final score to:
- 68% – changed definition (classes or modules)
- 13% – too many extra files
- 10% – too many files
- 9% – package file
Of these buckets, “changed definition” is the hardest, so it might be smarter to knock out the other three three first, and then circle back. Once we’ve solved all of these buckets, Sorbet will never fail to process an edit incrementally.
We haven’t won yet, but we’re getting close!