Here’s the elephant in the room: Sorbet’s syntax is ugly.
When people start complaining about Sorbet’s syntax, I have to spend a lot of time deflecting or even defending it, which is annoying: I’m right there with you, the syntax is ugly! It’s verbose. It’s foreign. It doesn’t resemble any typed language, nor does it complement Ruby’s unique style.
My counter is that when it comes to language design, semantics—what the types mean—are easily 10 times more important than syntax. This is what I was taught; it’s also what I’ve seen. Programming is an act of theory building, and when you sit down to write code, you’re trying to codify how you’re thinking about a problem as much as instructions for the machine. Types become a tool to help get the semantics from your head into the codebase. That’s a lossy process, and types fill a role kind of like “error correcting codes” for brain dumping.
So I try very hard to not get sucked into debates about syntax—in no small part because from where I stand, tons of the people complaining about the syntax also don’t like the semantics, they just don’t know how to say it. And not only do they not like Sorbet’s semantics, they don’t like statically typed semantics in the first place! Even if I changed their mind on Sorbet’s syntax, there’s basically no way I’ll change their mind on the idea of static types. So why bother? They’re not prospective Sorbet users no matter what I say.
But in thinking that way, I ignore the cohort of committed, enthusiastic Sorbet users who actually love the semantics but tolerate the syntax.
So that’s who this talk is for: I’m not here to convince you to start liking typing or to start using Sorbet! Instead, I want to lay everything out there, so that the people who are motivated by syntax more than me have a view of problem space and can channel their complaints into action.
We’re going to cover a lot of things:
- The historical context at Stripe that gave rise to Sorbet
- The goals and constraints which sprung from that historical context
- Various problems we discovered over time, forcing redesigns of the type syntax
- Potential future changes to the syntax, ranging from “yeah we should probably have done that yesterday” to “that sounds like it’ll never happen… but wouldn’t it be cool?”
The before times
Before we get too much further, I’ve forgotten to introduce myself: my name is Jake, and I’ve been working full time on Sorbet for almost 7 years.

I started at Stripe a month before the Ruby type checker project kicked off, and I joined the team 1 year later. Most of what I have to say here is from direct experience, from chatting with people over lunch, or from combing old emails. That means some of the things that happened before 2017 are a little hazy, but I’m going to do my best.
In mid 2017 (when I joined, and when Sorbet was starting) there were about 750 people at Stripe, of whom about 300 were engineers.
Every 6 months (to this day), Stripe runs a survey of all engineers at the company, asking them about about their productivity. In the first survey of 2017, engineers were asked to pick priorities for the Developer Productivity team by choosing three things from this list:
- Better technical documentation
- Static type checking for Ruby
- Unattended deploys
- CI flakiness on feature branch builds
- CI flakiness on master builds
- Async programming primitives and libraries
- Seamlessly start multiple services in development
- GUI for running database migrations
It’s in order by their responses: the top two were “better docs” and “static type checking.” Also, when looking at the free-form responses, the number of complaints mentioning themes of “code organization, interfaces, and modularity” had doubled from 6 months prior. Test speed, while substantially improved from the prior survey, was still a widespread call out.
One of those open-ended questions was: “What are the top 1-2 things we could do to make you more productive?” It got answers like these:
mono-repoing all the things; better, more intuitive code/documentation (clearer interfaces, static typing, stronger assurances from linting)
static types / less magic in [Stripe’s Ruby codebase]
builds being faster, tests on branches passing meaning you wont break master, static types in [Stripe’s Ruby codebase]
I mention all this to drive home that we didn’t build Sorbet because we wanted to, we built it because people were asking for it!
Which is also the reason it’s hard for me to give advice to people adopting Sorbet. They’ll ask me, “How did you convince people?” and I’ll say, “we didn’t: they convinced us!” But I’m getting off track, because I’m not trying to convince people to use Sorbet today.
Appetite for typing at Stripe
Why didn’t Stripe use mongoid, the official MongoDB ODM? I have no clue. The first mongoid commit predates the first Odin commit by about 4 years, so it’s not like there was no alternative.
We can dig a little deeper and see where this appetite for typing came from. As early as 2013, Stripe had developed its own object-database mapper for defining database models:
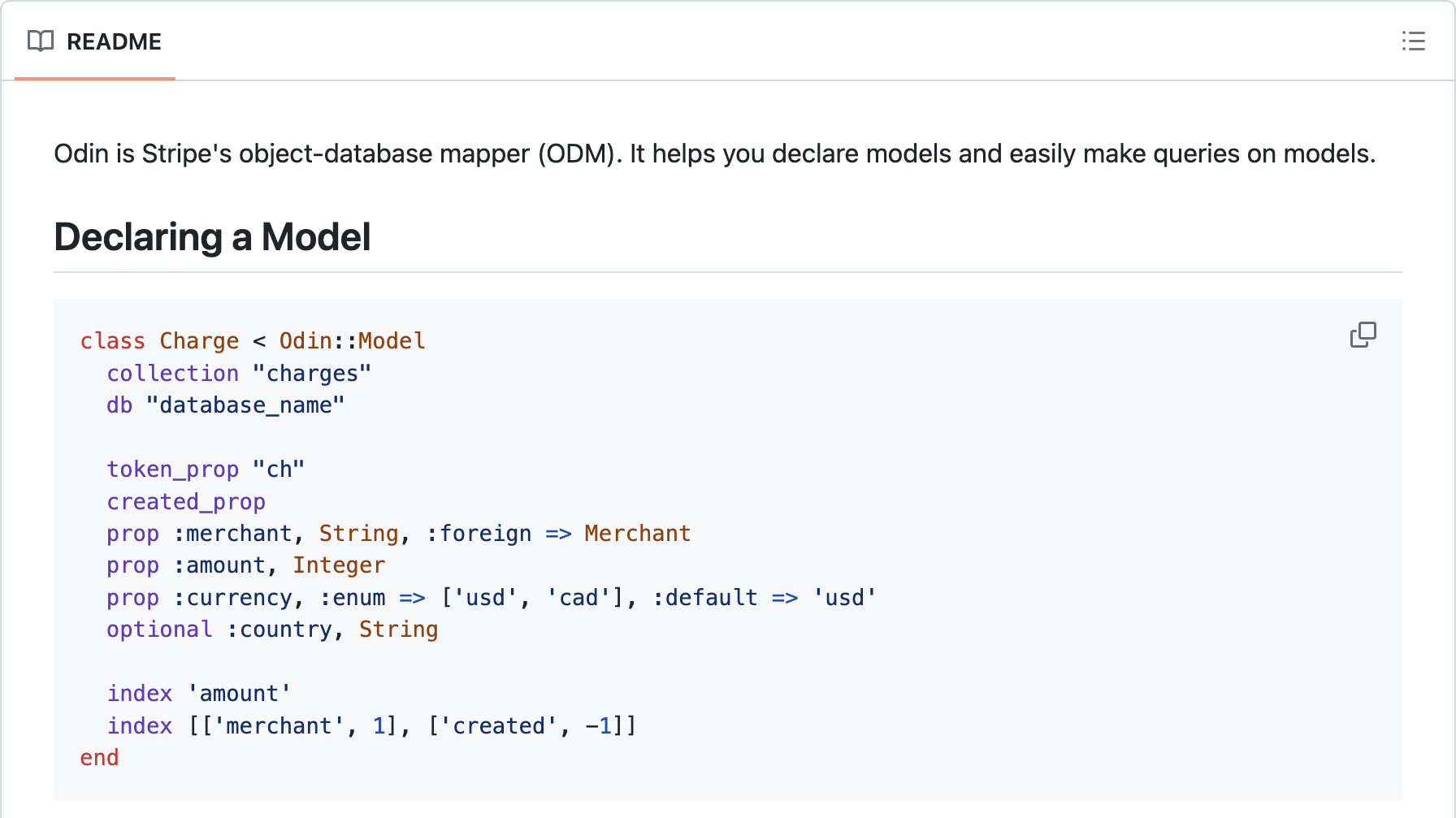
For anyone who uses Sorbet, this should look remarkably familiar:
it’s the exact same code you’d use to define a T::Struct today.
Like any good ODM (or ORM), it did type validation at runtime to ensure
that database write operations don’t store bad data.
Stripe also had a library for defining interfaces, circa 2013:

The idea was that an interface would expose a specific set of required methods. Then you’d box up a value of that interface, like
animal = Animal.from_instance(Dog.new)and the library would check that you implemented all the required
methods. Also, it prevented calling methods not in the
interface at runtime. So for example, animal.bark would
raise a NoMethodError, because bark isn’t in
the public interface of Animal. If you needed to call a
Dog-specific method, you’d have to explicitly downcast to a
dog:
animal.bark # 💥
dog = Chalk::Interface.dynamic_cast(animal, Dog)
dog.bark # ✅If you called dynamic_cast on something that was not a
Dog, you get back nil, like how
dynamic_cast works in C++.
You should be seeing a pattern here: most of Stripe’s appetite for typing manifested as Ruby DSLs for runtime checking and declaring explicit interfaces. This came to an inflection point in November 2016—almost a year before Sorbet—when Stripe implemented what it called “interface constraints.”
For the Stripe employees playing “spot the
anachronism,” this screenshot should have been of a Hackpad, but that’s now
long gone.

It was a library for wrapping methods with runtime type checking,
mimicking a primitive form of “design by
contract.”In a recurring theme, there were already libraries
for “design by contract” in Ruby, like contracts.ruby,
that Stripe chose not to use. I can’t find mention of them influencing
Stripe’s “interface constraints proposal,” but in retrospect I think it
was important for Stripe to have control over the evolution of Sorbet’s
type syntax.
This library directly evolved into Sorbet’s sig syntax,
and it worked the same way: the library allowed declaring a
specification for a method, and then wrapped the following method with
runtime type checks.
The proposal mentions maybe one day building static checking for these annotations, but that was mostly hypothetical: runtime checking was the point from the beginning. Ruby is a language all about the neat things you can do at runtime!
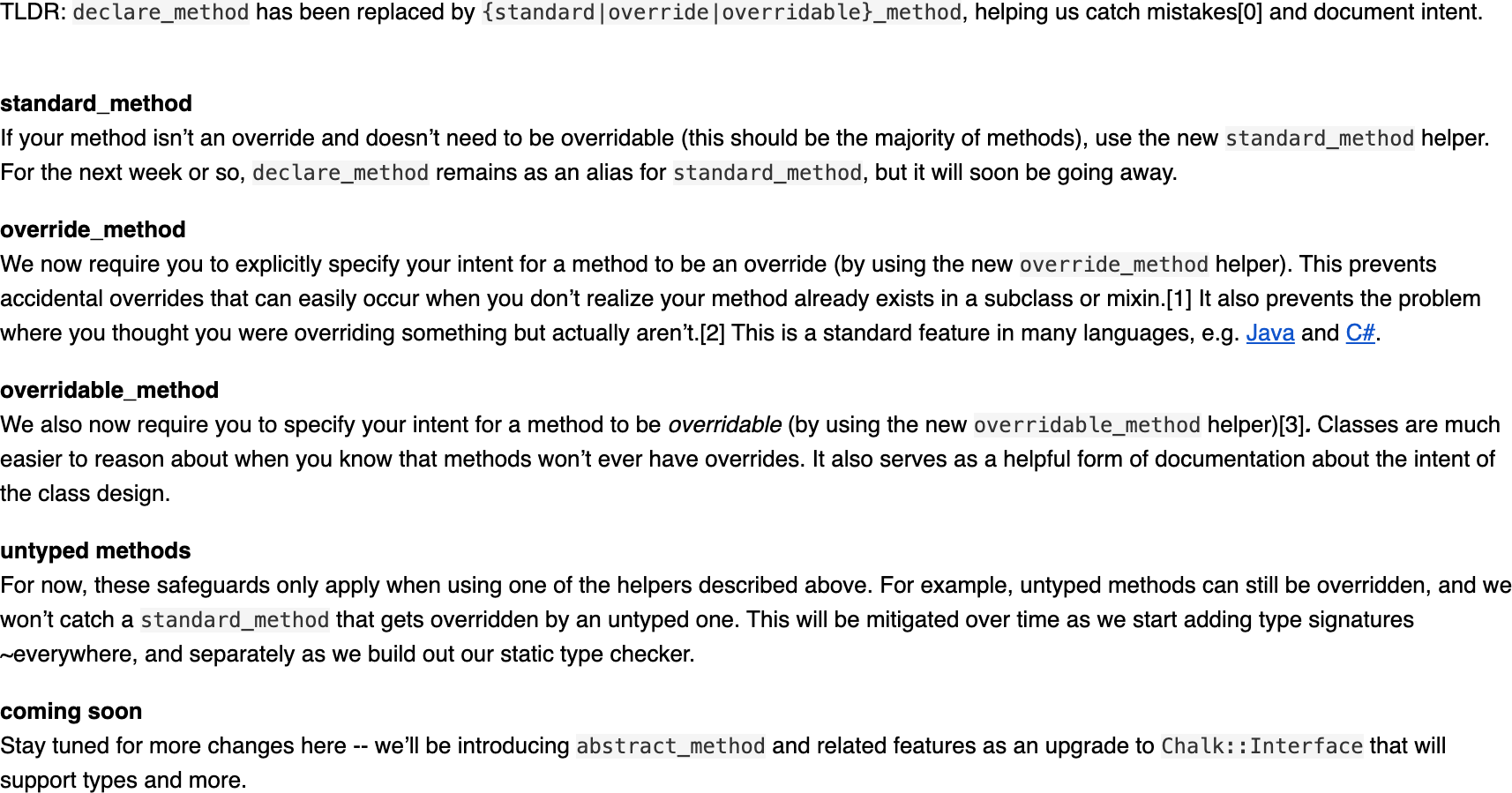
Later, this declare_method library gained support for
declaring overridable and abstract methods, which let it replace the
Chalk::Interface library (so that interfaces could talk
about required signatures, not just required methods):
Throw in the fact that the JavaScript codebase powering Stripe’s
dashboard gained support for static typing in July 2016 (via FlowWhile researching, I came across the original
Flow announcement from 2014, which is interesting in understanding
its original design goals.
), and the stage was set. Desire for Ruby static typing
came to a flash point in the first half of 2017. A particular email
(which has been lost to the sands of retention) from an influential
engineer at Stripe called out the difficulty of making sense of Stripe’s
Ruby codebase given its size and evolution, alongside specific,
high-profile instances where a static type checker would have eliminated
those problems.
The design of a type syntax
The team evaluated various approaches:
Rewriting to a typed language wouldn’t work: Stripe had almost 2 million lines of Ruby code at the time, and as we’d say at Stripe, “we haven’t won yet,” which is a way of saying the work never stops. There’s no time to pause all feature development and rewrite to another language, because that wouldn’t make our users’ lives better.
There mostly weren’t any existing type checkers for Ruby. There’s a project called RDL, but it’s kind of a hybrid static+runtime checker. RDL’s “static” checking happens after eagerly loading all the code and using the Ruby VM to do most of the symbol lookup. At the time, eagerly loading all of Stripe’s code (not even asking RDL to check types) took a few minutes—by comparison, the first version of Sorbet ran in a few seconds.
There was also a project called TypedRuby, largely a passion project of an engineer working at GitHub. After a few weeks of evaluation, it seemed that there were enough bugs in the project that fixing them would involve a near complete rewrite of the project anyways.
So the team decided to write something from scratch, which meant being tasked with designing a type syntax. Let’s look at some approaches.
The TypeScript approach: add types on top, compile them away
The most obvious approach in retrospect is the approach that has worked spectacularly for TypeScript: build our own syntax, free of any constraints in the source language, and compile it away with a build step.
For Sorbet this would have meant a massive break with Ruby compatibility. In the JavaScript world, minifiers, tree shakers, transpilers, and compile-to-JS languages were everywhere. Most developers gave up the “save file, reload page” development paradigm ages before TypeScript became popular: CoffeeScript predated TypeScript by 4 years.
But even today, I’m not aware of a single Ruby codebase of significant size that has a source transform build step that blocks running the tests or reloading the service. Ruby engineers expect to run tests directly and to be able to reload a service immediately after saving a file. Introducing a mandatory build step that blocked running a test would have been a big point of friction.
Even if Stripe was okay self-imposing a build step, it would break virtually all Ruby dev tools. Linters, syntax highlighting, and code formatting would break. Observability tools would show backtraces in the wrong spots, because the Ruby VM doesn’t have source mapping. IDEs like RubyMine would fall back to being text editors.
Let’s say we built all those tools, too. We wanted to open source Sorbet one day: this was a top-line goal right in the project brief. If anyone were ever to adopt Sorbet, it would need to be gradual: to not require fundamentally reworking how the codebase builds, tests, and deploys code just to try it out. Adopting a build step is a huge “all or nothing” decision for a codebase.
The header file approach: like what RBS is today
If we can’t change the source syntax, maybe we make our own syntax for declaring types? Every source file could be paired with a kind of “header” type definition file that declares the types.
Basically all gradual languages end up supporting this anyways:
TypeScript has *.d.ts, Python has *.pyi.
Sorbet has *.rbi files, and Ruby eventually shipped
*.rbs. You need these files to declare types for files
completely outside your control: third-party gems, things defined in
native extensions, etc.
The problem is that they’re only half of a solution: even if you use
RBS files to annotate methods, you’ll still need explicit type
casts inside method bodies. RBS files alone don’t have a way to
say, “trust me, right here I know that this variable is an
Integer.”
I will say: the nice thing about this approach is that you’re free to choose a syntax that’s as clean as you want: it’s a blank slate on type syntax design, with virtually zero constraints, even more blank than the transpiler approach. We’ll come back to this later.
The JSDoc approach: types in comments
If the types needs to be in the source, and we can’t change the syntax, maybe we’ll invent our own syntax in comments? Google’s Closure Compiler chose this strategy well before TypeScript appeared, and Ruby already had a history of comment-based type annotations via tools like YARD. Sorbet could have formalized a rigid type-based comment syntax, and used that for both method signatures and inline type casts.
But here we return to the issue of runtime checking: Stripe engineers were asking for static and runtime type checking, not static instead of runtime!
You get a lot for free if you decorate a method with runtime checking, most important being the guarantee that no one can Hyrum’s Law your method:
With a sufficient number of users of an API,
it does not matter what you promise in the contract:
all observable behaviors of your system
will be depended on by somebody.
Consider code like this:
def get_mcc(charge, merchant)
return charge.mcc if charge
merchant.default_mcc
endIf charge is non-nil, we return early
before checking whether merchant is nil or
not. Now suppose we need to edit the method to implement a new “merchant
override MCC” feature:
def get_mcc(charge, merchant)
override = merchant.override_mcc
return override if override
return charge.mcc if charge
merchant.default_mcc
endThis new override is meant to take precedence over any “MCC” on a
charge. Is this change safe? Callers were supposed to be passing in a
non-nil merchant into this method, but maybe some weren’t?
If we aren’t sure, now we have to be defensive, which is annoying and
maybe causes other problems!
But this problem vanishes when making a changes in methods with runtime-checked signatures.
sig { params(charge: Charge, merchant: Merchant).returns(MCC) }
def get_mcc(charge, merchant)
override = merchant.override_mcc
return override if override
return charge.mcc if charge
merchant.default_mcc
endIf the signature says it’s non-nil, we can rely on that
invariant throughout the method body, in all conditionals. Adding a new
call to merchant.override_mcc cannot cause net new
uncaught NoMethodError exceptions as long as the method
already had a runtime-checked sig. In a growing codebase
with changes from hundreds of people, runtime checking ensures code
remains flexible without fear.
A comment-based approach to type syntax would have meant giving up on runtime-checked signatures. Again: runtime checking is a unique strength of Ruby’s dynamism!
The DSL approach:
declare_method becomes sig
The approach that Sorbet picked was to repurpose Stripe’s
declare_method DSL. As a benefit, it meant that the project
immediately gained thousands of trustworthy annotations to use as a
proving ground for the implementation.
Before we dive into specific considerations for the DSL approach, I want to take a second to marvel at the fact that this approach even works at all. It’s wild, isn’t it? Decorate a method with a single line—in a language that doesn’t have first-class decorators!—and the following method gets runtime checking. You can try to approximate this with higher-order functions in JavaScript, but it doesn’t look anywhere near as good.
At the same time that declare_method shortened to
sig, type syntax shortened from things like
Opus::Types.any(NilClass, String) to just
T.nilable(String).
Truly, while I was researching this topic, I found so many wacky old syntaxes, far too many for this post. If you want the details feel free to ask me.
The specific syntax that sig uses evolved a handful of
times
and I want to talk about those changes, but not before considering one
final approach.
The Python approach: first-party type hints
Support for typing in Python went differently. Way back in 2007, a proposal for “Function Annotations” was accepted:
def foo(a: expression, b: expression = 5):
...The idea was that annotations would be completely devoid of meaning, so that various tools could ascribe their own. As in: you could stash arbitrary strings there and use them for documentation, or you could put class names there and use them as types, etc. Even at the time it was accepted, people were already discussing interoperability of various project’s annotations, and eventually in 2015 a follow up proposal formalized Type Hints, saying essentially, “You don’t have to use Function Annotations for types, but if you’re going to, you should follow these conventions for what the types mean.”
The annotations play to the strengths of Python as a dynamic,
runtime-focused language. They’re not static-only annotations that get
compiled away like TypeScript: they’re present at runtime via the
__annotations__ property, and annotations can evaluate
arbitrary code! The Python VM does not use them for runtime checking,
but multiple,
third-party libraries provide
decorators that do.
For Python, this approach has a lot going for it:
- It’s a first class syntax that feels at home with other parts of the language’s syntax.
- Individual projects can choose whether they want runtime checks or not.
- The annotations are always present at runtime for third-party tools to consume them directly.
The obvious downside is that it requires a change to the VM. In the planning phase of Sorbet, it would have been a non-starter to ask the Ruby team to invent syntax for us.
… but if you squint, Sorbet’s DSL approach is almost the same as this type hint approach!
- Both treat annotations as completely optional.
- Both treat annotations as runnable syntax, allowing the full flexibility of the language.
- Both allow for optional static and optional runtime checking.
- Both provide a reflection API to get the annotations at runtime.
The biggest difference is just the syntax—both offer the semantics that we need! When Sorbet started with the DSL approach, a selling point was that it would be easy to migrate to a blessed, upstream type hint approach if that ever became an option.
The type hint approach has unfortunately stalled for Ruby. I have more thoughts on this, but for now let’s keep retracing the evolution of Sorbet’s DSL syntax.
Types are expressions
Both the DSL approach and the type hint approach share the feature that types are expressions. This leads to three big constraints on the design of a syntax.
When the syntax we want is taken
When types are expressions, sometimes type syntax you want already has another meaning.
It would be really nice to use | for union types,
& for intersection types, and [] for
generic types, directly on class or module names:
Integer | String # Module#|
Runnable & HasOwner # Module#&
Box[Integer] # Module#[]There are two problems:
It would involve monkey patching
Module, which would be controversial, and thus need to be opt-in: this syntax could not be the sole accepted syntax.Some singleton classes may already define these methods.
ArrayandSetare examples from the standard library:Array[1, 2, 3] # Array.[] # => [1, 2, 3] Set[1, 2, 3] # Set.[] # => #<Set: {1, 2, 3}>While we’re in the realm of the wacky, we could have “block-scoped” monkey patches where we replace the meaning of certain methods when evaluating the
sigblock to make this work, but the earlier point stands: some people won’t want that.So
Array[Integer]would not make a generic type, but rather a length 1 array:[Integer].
Something similar comes up for tuples: the | and
& methods already mean something for Arrays:
[1, 3, 5] | [2, 4, 6] # Array#|
# => [1, 3, 5, 2, 4, 6]
[1, 2, 3] & [2, 3, 4] # Array#&
# => [2, 3]In this case, it might be easier to abandon using raw
Array literals for tuples, and instead use a syntax like
T[Integer, String] to define a tuple, freeing up
| and &.
While building Sorbet, our goal was to have one way to do things, for consistency. Maybe it’s time to relax that? If Ruby is okay having three names for filtering a list, maybe Sorbet can be okay having more than one way to specify union types. We could let individual codebases decide which syntax they want to use.
Forward references
When types are expressions, you have to worry about forward references in type syntax. The evolution of the DSL syntax looked like this:
declare_method({x: Integer}, returns: String)
standard_method({x: Integer}, returns: String)
sig.params(x: Integer).returns(String)
sig { params(x: Integer).returns(String) }The most recent change switched to specifying types inside a block,
which was done so that adding a sig wouldn’t cause
load-order problems. For example:
class A
sig.params(x: MyData).void
def self.example(my_data)
puts(my_data.foo)
end
MyData = Struct.new(:foo)
end
A.example(MyData.new(42))There’s no problem loading this file, until you add a
sig (pictured using the old, eager syntax). Even though the
MyData#foo method is called on line 4, above its definition
on line 7, that doesn’t matter because example isn’t called
until line 10.
But adding the sig breaks that: there’s now a forward
reference to MyData which the sig evaluates eagerly,
causing an exception at load time. This kept causing problems as people
added more sig’s. The problem was worse because of
autoloading: in development everything might have looked fine, because
you only evaluated things in a certain order, but then in CI or
production things loading in a different order would bite you.
Hiding all the types inside a block switches signatures from evaluating eagerly to lazily: the runtime implementation defers forcing the block until the first call of the method. These days, you basically only get a load-order issue if the code already had a load order issue.
It’s interesting to point out that Python type hints went through a very similar growing pain, and in newer versions of Python you can write:
from __future__ import annotationsto convert type hints from being evaluated eagerly to lazily. The proposal introducing it is very well written and has a great summary of the history and problems.
Sometimes you really want custom syntax
When types are expressions, you’re limited by what’s valid Ruby syntax. There’s a lot of alternative syntaxes that would be really nice for type syntax:
Integer?instead ofT.nilable(Integer)(Integer) -> Stringinstead ofT.proc.params(arg0: Integer).returns(String)|and&without monkey patches
The other approaches (transpiler, RBS files, documentation comments) don’t have this limitation: with those approaches you’re free to pick any syntax you want.
There’s a lot that can still be done while operating under the “types as expressions” constraint, but there’s no denying that if you give that up, you can get some really terse type syntaxes.
Where we go from here
What’s next for Sorbet’s type syntax? We’ve learned a bunch of constraints in the design space:
- It can’t break compatibility with Ruby, or no one will use it.
- We need a syntax that works for runtime checking too, because Ruby is a runtime-focused language at its core.
- There’s only so far you can go with “types as expressions,” but we could probably go a little further with optional monkey patches.
- Adding a signature can’t cause code to load out of its usual order.
So this leads to a few next steps:
- Probably we should build opt-in support for syntax that requires monkey patches?
- We can think about some backwards-incompatible changes, like to how tuple types are declared.
- We can think about making some super-verbose things (like generic methods) less verbose.
But I want to suggest one more option, which is a bit more radical: what if the Ruby VM parsed RBS comments and associated them with method definitions?
class A
#: (Integer) -> String
def self.foo(x)
end
endSoutaro introduced this comment-based syntax for RBS at RubyKaigi in 2024. It’s a syntax that both Steep and TypeProf understand, and that Sorbet is gaining support for. Right now it’s just in comments… but what if the Ruby VM actually parsed these comments and exposed them at runtime?
A.method(:foo).rbs_annotation
A.rbs_annotation(:foo)If RBS comments were exposed by the Ruby VM like this, it wouldn’t force people to choose between Ruby’s elegant RBS syntax and Sorbet’s powerful runtime type checking.
It also solves some of the problems with “types as expressions,”
because types wouldn’t be expressions anymore: the Ruby VM would choose
how to parse these annotations, meaning that we still get terse syntax,
able to use | and [] free of other
constraints. It would also fix the forward reference problem because the
VM wouldn’t be evaluating these comments, just parsing them for other
tools to consume. Those tools might attempt to resolve constant names,
but that’s up to each tool to figure out when and how to do that.
Having RBS annotations available at runtime would be useful for more than just Sorbet:
- IRB could use these annotations to show completion results, without having to parse RBS comments separately and associate them with the methods.
- Gems could get creative with how they use it. For example, you could
imagine a JSON Schema library where the schemas are defined by
collecting all the type hints in a
StructorDataclass. - Linters could piggy back off the Ruby VM’s parser and be able to pass along the parsed RBS annotations to custom linter rules, so that lint rules don’t have to parse the annotations themselves.
Given that it starts from a comment-based syntax, you could still make it be optional, something that doesn’t affect you at all unless you want it to.
This solution isn’t a silver bullet: it wouldn’t do anything for
T.let assertions where you want to make an assertion for a
specific value at runtime, but it’s a great start!
In the end, all I’m trying to say is: we don’t have to think of Sorbet’s syntax as “done.” Even if Ruby never adds support for type hints, we can keep improving Sorbet. But also it’s an exciting time for type annotations in Ruby itself, and I remain optimistic for the future of the wider Ruby typing ecosystem.